I am building a macOS menu-bar app that listens to live disk I/O and plays back the mechanical chatter of a 1990s hard drive in response. The synthesis engine is the whole point, and my first one was wrong in a way that took a while to hear: it modelled the wrong motor. This is the log of getting from that first engine to one that actually clicks.
The target was a single reference recording — a clean capture of an old PC drive seeking and chattering.
First engine: the wrong motor
The intuitive picture of an old hard drive is a stepper motor: discrete steps, a buzz whose pitch tracks the step rate. So the first synth was exactly that — a train of per-step impulses, the fundamental pitch following the commanded step rate, harmonics from the near-square torque pulse. It sounds mechanical. It even sounds old. It just doesn’t sound like the thing I was chasing.
That buzz is real, but it belongs to a different class of drive. Which is the part I had backwards.
The reversal: it was never a stepper
When I went back to the source material instead of my assumptions, the picture inverted.
There is a real evidence gap here, and it is worth stating plainly: there is no published instrumented acoustic spectrum of the specific vintage parts. The model that follows is extrapolated from documented OEM seek timings, voice-coil-motor patents describing the noise mechanism, and the reference recording — and where it is extrapolated, it is flagged as such. This is physically-motivated synthesis, not a reconstruction of a measured drive.
The first thing the reference clip got me was structure. Slicing it into individual click events and projecting them down shows the clicks are not one sound — they fall into families (a darker, longer body and a brighter, sharper attack), which is consistent with a two-transient seek whose two current edges vary in relative weight as the seek distance changes.
Rebuilding from voice-coil physics
The rewrite replaced the stepper synth with a voice-coil seek voice. Three documented mechanisms, layered per seek:
- Bang-bang seek current → two transients. The voice-coil current during a conventional seek is essentially a square wave: a positive pulse accelerates the head, a negative pulse brakes it. Each current edge is a broadband impulse that excites the actuator. Seagate patent 6,937,428 puts it directly — the “abrupt application of current… to quickly accelerate and decelerate” gives “broad spectrum excitation of the actuator” — and the earlier 5,760,992 describes the same seek noise in its own terms, the actuator “blow” setting up “resonant vibrations in the actuator… to produce readily audible noise.” For a short seek the two edges merge into one click; for a long seek a coast phase separates them into a distinct launch and arrival.
- Crash-stop impact. The actuator’s travel limits are elastomer bumpers; the head arriving against one produces the end-of-stroke “thunk.”
- Settle ring. The abrupt arrival excites lightly-damped arm resonances (~0.8–3.8 kHz) that ring down after the head lands.
In the lab the voice is a single function. Trimmed for readability, the core is:
| |
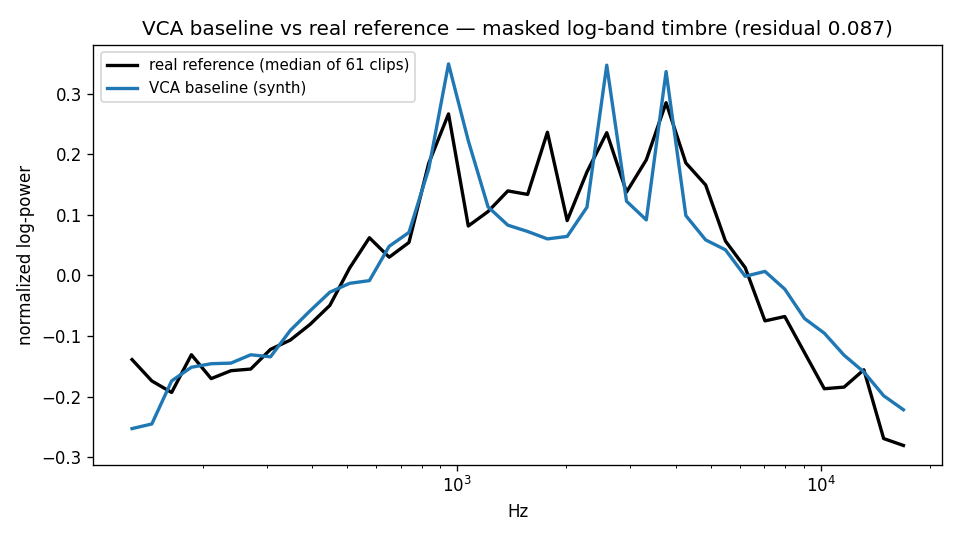
The free parameters — the three resonance modes, their gains, the decay, the crash level, the current band — are not hand-tuned. An autofit harness fits them to the cleaned reference set (61 click clips) against two objectives: eight scalar landmark features (attack time, ring-down, spectral centroid, mid- and high-band energy ratios, ring peakiness, and the two arm-resonance peaks), each scored against a [p25, p75] tolerance band taken from the reference set, plus a masked log-band spectral cosine over the bands that sit above the recording’s noise floor. The fit is the part I trust the most, because it has a number on it.
The fitted timbre is frozen as a preset; the runtime drives only two knobs on top of it (pitch, damping) plus the per-seek distance.
Hearing the difference
This is the rewrite that justified itself. Play the voice-coil voice against the two stepper clips above — same two moves, different machine.
A long move: where the stepper buzzed, the voice-coil splits into launch and arrival.
A short move: where the stepper still buzzed, the voice-coil collapses to a single tight click.
And a burst of random-access seeks — the kind of texture the app produces under load:
The cabinet matters too
A bare seek voice still sounds synthetic, because much of what you hear from a real drive is the box. A 3.5" HDD case is far too small to reverberate — its Schroeder frequency sits near the top of the audible band (≈ 20 kHz for a box that size), so there is effectively no diffuse-field regime inside the audio range. It cannot be modelled as a reverb. Instead it is treated in the modal regime: a bank of rigid rectangular-cavity eigenmodes (the resonant body) plus image-source early reflections (the metallic attack ring). The two describe the same physical field, so they are exposed as independent amounts rather than summed at full strength, which would double-count the energy.
A dry seek, then the same seek through the two layers and the blend, in a 3.5" cavity:
The cavity geometry is a parameter. A 2.5" laptop-drive enclosure is a smaller box, so its modes sit higher and tighter — the same seek reads as a harder, drier click:
And the difference is clearest on a chatter burst, where the cabinet glues the individual clicks into one continuous body:
From disk I/O to clicks
A real seek voice still needs something to seek to. The app’s input is `fs_usage` disk-I/O events, and the mapping between an I/O event and a sound went through its own correction. The first version filtered and rate-limited the event stream — and that averaged out the per-event arrival timing, which is exactly the information that carries the drive’s rhythm. Removing the filtering and sonifying events closer to 1:1 brought the rhythm back; the current version coalesces them into activity-driven chatter so a continuous backend produces continuous sound without flooding the UI.
One host I/O does not map to one seek physically, either. Each operation is expanded into a cluster of seeks — a read pulls directory, allocation table, and data regions; a write coalesces — with the seek distances drawn from a measured distribution.
Takeaway
The first engine was not badly tuned; it was the wrong model. No amount of parameter tweaking on a stepper synth was going to produce a voice-coil click, because the stepper and the voice-coil are different machines making different noises. The fix was not in the synth — it was going back to the documented physics of the part that actually makes the sound, fitting the free parameters to a real recording instead of by ear, and putting a number on how close the fit got (≈ 0.087 spectral residual). The cabinet and the I/O-to-seek mapping are the same story in miniature: get the physical model right first, tune second.